
10.2. Volatility Timing#
Recall our earlier formula
Before we had \(x_t=\frac{E_t[r_{t+1}-r^f_{t+1}]}{\gamma Var(r_{t+1})}\)
Now we will look at the other extreme \(x_t=\frac{E[r_{t+1}-r^f_{t+1}]}{\gamma Var_t(r_{t+1})}\)
(note the subscripts!!! )
Important
The crucial necessary condition for this to work is that there is no time-series relationship between alphas and vols (or at the very least that this relationship is weak enough)
\[cov(\alpha_{i,t},\sigma^2_{i,t})=0\]
This is key. Might or might not be true depending on asset/strategy.
But tends to be true.
This only works if the alpha/premium is positive to begin with
If Sharpe ratio is zero, you can’t increase it by managing risk!
This is also true for market timing! You can see that if variance and expected returns moved tightly together you would never trade!
Note that both things can happen at the same time, as long they don’t move exactly together you can time both!
One can think of minimum-variance investing in the time-series–just like if you believed expected are constant across assets
For any trading strategy the volatility timing portfolio is \(w_i=\frac{\alpha_i}{\sigma_{i,t}^2}\)
Note
If Alphas are time-varying but Sharpe ratios are constant, i.e. \(\alpha_{i,t}=k\sigma_{i,t}\), then the optimal allocation becomes proportion to inverse volatility \(w_i=\frac{\alpha_i}{\sigma_{i,t}}\).
10.3. Volatility Timing the market#
ALAN MOREIRA, TYLER MUIR, Volatility-Managed Portfolios, Journal of Finance, August 2017 https://doi.org/10.1111/jofi.12513
Show that this logic works for the market and many other factors.
Since then a huge literature has emerged showing that volatility managing is a great way to boost Sharpe Ratios
The construct portfolios
The key is to construct a good measure for \( Var_t(r^e_{t+1})\)
We will do something simple and use past vol as a proxy for future vol
Of course whether is a good proxy or not depends of how it plays out in the data
But we already saw that for the market past vol dos a really good job
Using daily data for month t, construct the market return “realized variance” during month t like we did in our estimation sample lecture
\[rv_t=\sum_{d \in days~ in ~month ~t}\frac{(r_d- \overline{r})^2}{N_{days}},\]
where \(\overline{r}\) is the average return within the month
We will need daily data to do this
df_factor = get_factors()
df_factor.head()
c:\Users\alan.moreira\Anaconda3\lib\site-packages\pandas_datareader\famafrench.py:114: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
df = read_csv(StringIO("Date" + src[start:]), **params)
| RF | Mkt-RF | |
|---|---|---|
| Date | ||
| 1926-07-01 | 0.00009 | 0.0009 |
| 1926-07-02 | 0.00009 | 0.0045 |
| 1926-07-06 | 0.00009 | 0.0017 |
| 1926-07-07 | 0.00009 | 0.0009 |
| 1926-07-08 | 0.00009 | 0.0022 |
Constructing monthly realized variance from daily data
You basically use pandas time series function that shifts all dates to the end of the month, so this way you are technically grouping by the end of the month day. We did this before!
We then will do the same with our daily returns to get monthly returns
RV=df_factor[['Mkt-RF']].groupby(df_factor.index+pd.offsets.MonthEnd(0)).var()*252
RV=RV.rename(columns={'Mkt-RF':'RV'})
# aggregate daily returns to monthly returns
Ret=(1+df_factor).groupby(df_factor.index+pd.offsets.MonthEnd(0)).prod()-1
# Merge Ret (monthly return) with RV (realized variance and weights)
df=RV.merge(Ret,how='left',left_index=True,right_index=True)
# construct excess returns
# lag RV by one month
df['RV_lag']=df['RV'].shift(1)
df.mean()
RV 0.028825
RF 0.002691
Mkt-RF 0.006896
RV_lag 0.028841
dtype: float64
10.3.1. Intuition#
Before build the strategy it is useful to see WHY it works
For Vol timing to payoff we need that
when vol goes up the risk-return trade-off goes down
When vol goes dow the risk-return trade-off goes up
One way to see if that is true in the data is to sort all months by past vol in buckets
In bucket 1 go the really low vol months
In bucket 5 the really high vol months
We then look at how vol and returns were the month after–i.e. we group the month vol and the month return by past vol!
# Create quantile groups based on the RV variable
# pd.qcut splits the 'RV_lag' column into 5 quantile-based groups,
# meaning they group the data into 5 equal-sized bins based on the values of 'RV_lag'.
# ensuring that each group has approximately the same number of observations.
df['Quantile'] = pd.qcut(df['RV_lag'], q=5)
# Group by quantile and calculate the mean for each column
quantile_means = df.groupby('Quantile').mean()
# label the index according the volatility of the highest vol month in the quantile
quantile_means.index = quantile_means.index.map(lambda x: round((x.right)**0.5, 3))
# compute the price of risk--i.e. the ratio of the mean excess return to the mean realized variance
# across the months in each quantile
# importantly these are for the future months, i.e. the mean excess return and variance for month t+1
# while we used the variance for month t
quantile_means ['priceofrisk']=quantile_means['Mkt-RF']*12/(quantile_means['RV'])
# Display the mean of quantiles for each column
fig, axs = plt.subplots(3, 1, figsize=(10, 12), sharex=True)
((quantile_means.RV*12)**0.5).plot(kind='bar', ax=axs[0])
axs[0].set_title('Realized Variance (RV(t+1)) by RV(t) Quantile ')
axs[0].set_ylabel('Vol(t+1)')
(quantile_means['Mkt-RF']*12).plot(kind='bar', ax=axs[1])
axs[1].set_title('Market Excess Return (t+1) by RV(t) Quantile')
axs[1].set_ylabel('Mkt-RF')
quantile_means.priceofrisk.plot(kind='bar', ax=axs[2])
axs[2].set_title('Price of Risk by Quantile by RV(t) Quantile')
axs[2].set_ylabel('Price of Risk')
axs[2].set_xlabel('Quantile')
plt.tight_layout()
plt.show()
C:\Users\alan.moreira\AppData\Local\Temp\ipykernel_29908\2575752801.py:9: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning.
quantile_means = df.groupby('Quantile').mean()
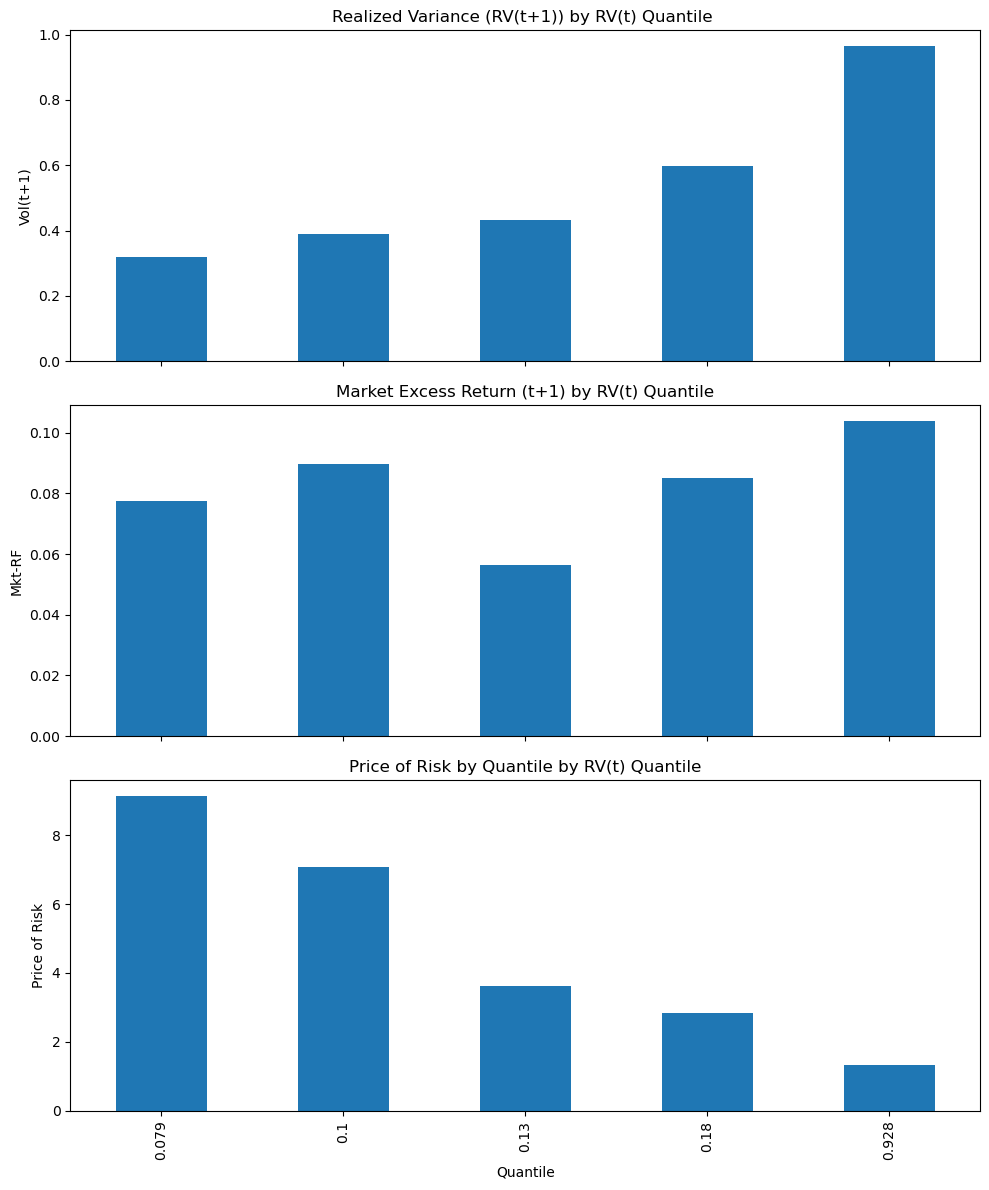
We see that following months of high variance–on the right– you don’t really get higher returns
if you focus on the ratio – the price of risk
you see that it is massively decreasing with variance
Average returns are not constant–but are close to–
so the natural strategy to exploit this pattern is to lever up when vol is low and reduce exposure when vol is high.
10.3.2. From signal to weights#
Specifically we buy the market at the closing price of month t according to the rule:
where \(c\) is some constant.
If you want to be very formal you could set \(c=\frac{E[r^{MKT}_{t+1}-r^f_{t+1}]}{\gamma}\)
But this only controls you average position in the market–and doesn’t say anything about timing
Hold the position for a month
The returns of the strategy are given by
\(c\) controls how levered is the strategy on average.
Here lets keep it simple and simply choose it so that the position on the market is 1 on average
implies \(c=\frac{1}{E[\frac{1}{rv_t}]}\)
df['Weight']=1/df.RV_lag
c=1/df['Weight'].mean()
df['Weight']=c*df['Weight']
df.Weight.plot()
df.Weight.mean()
1.0
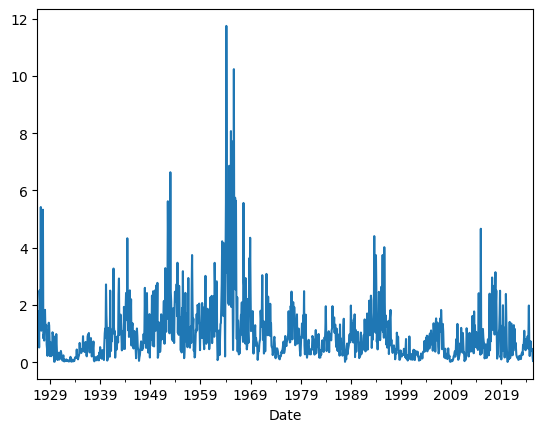
You see that leverage gets really high.
As high as 10!
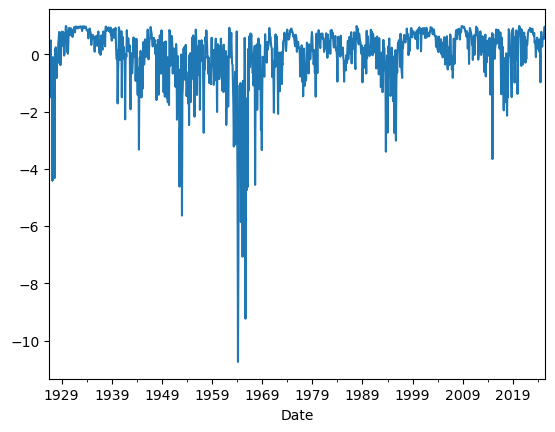
You can see that in your position in the risk-free rate which exactly mirrors that
# plot the weights on the risk-free rate
(1-df.Weight).plot()
plt.show()
10.3.3. Construct strategy returns#
Now to construct the strategy return recall that we use the realized variance in month t to buy the market at the closing of month t and earn the return accrued in month t+1
I will call the strategy as \(\textbf{VMS}\) (Volatility Managed Strategy)
# now construct the return of the strategy
df['VMS']=df.Weight*df['Mkt-RF']
We can see the cumulative returns of the market and the volatility managed strategy
df[['Mkt-RF','VMS']].add(df['RF']+1,axis=0).cumprod().plot(logy=True)
<Axes: xlabel='Date'>
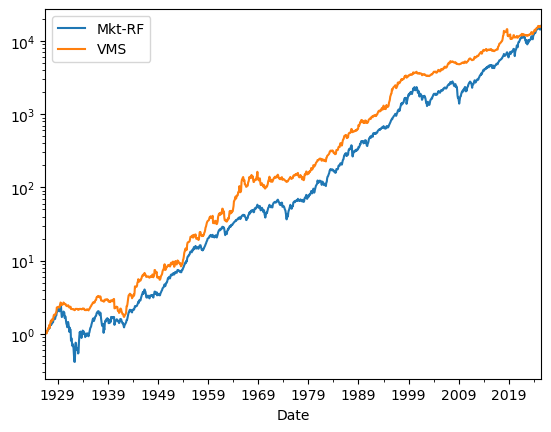
Does it work or not?
How to evaluate?
What should you look at?
Things to try
How well it works with VIX instead of RV?
What If we use a forecasting model to predict variance?
How well it works with standard deviation instead of variance
How well it works if we put leverage limits
How well it works if we combine an expected return signal with the volatility signal?
What about the other factors? Does it work there as well?
Before copying and pasting this code 20 times, simply put it all together in a function
As you try different things adjust the function to be more flexible
Below is the basic vol managed strategy
It returns the time-series of the strategy returns, but you should all the outcomes you are interest on
def volmanaged(df):
factor=df.name
df=df.dropna()
endofmonth=df.index+MonthEnd(0)
Signal=df.groupby(endofmonth).apply(lambda x: ((x-x.mean())**2).sum())
Signal=1/Signal.shift(1)
Signal.name='signal'
Ret=(1+df).groupby(endofmonth).prod()-1
df=pd.DataFrame(Signal).merge(Ret,how='left',left_index=True,right_index=True)
df['Weight']=df.signal
df['Weight']=df['Weight']/df['Weight'].mean()
df[factor+'_volmanaged']=df.Weight*df[factor]
return df
df_factor = get_factors('FF6')
volmanaged(df_factor['MOM'])
c:\Users\alan.moreira\Anaconda3\lib\site-packages\pandas_datareader\famafrench.py:114: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
df = read_csv(StringIO("Date" + src[start:]), **params)
c:\Users\alan.moreira\Anaconda3\lib\site-packages\pandas_datareader\famafrench.py:114: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
df = read_csv(StringIO("Date" + src[start:]), **params)
c:\Users\alan.moreira\Anaconda3\lib\site-packages\pandas_datareader\famafrench.py:114: FutureWarning: The argument 'date_parser' is deprecated and will be removed in a future version. Please use 'date_format' instead, or read your data in as 'object' dtype and then call 'to_datetime'.
df = read_csv(StringIO("Date" + src[start:]), **params)
(MOM 0.462232
MOM_volmanaged 0.906813
dtype: float64,
MOM -0.159845
MOM_volmanaged -0.085163
Name: 0.005, dtype: float64,
signal MOM Weight MOM_volmanaged
Date
1926-11-30 NaN 0.014683 NaN NaN
1926-12-31 2277.092450 0.002114 0.589074 0.001245
1927-01-31 2662.927643 0.035187 0.688888 0.024240
1927-02-28 2568.855606 0.000668 0.664552 0.000444
1927-03-31 3769.446919 0.045621 0.975140 0.044487
... ... ... ... ...
2024-08-31 599.322929 0.048827 0.155042 0.007570
2024-09-30 1049.077765 -0.000230 0.271392 -0.000062
2024-10-31 1164.418175 0.036818 0.301230 0.011091
2024-11-30 1582.413470 0.005364 0.409363 0.002196
2024-12-31 908.504923 0.000585 0.235026 0.000138
[1178 rows x 4 columns])